Past Art Vol 2: About a Year of It
There’s a folder on my computer that is named stupid_bullshit_projects that continually fills up with the things that i make and never end up telling anyone about. It is never in a hurry to get filled up, and so I add to it in limps and startles.
This last year was an especially good year for stupid_bullshit_projects because I was doing anything I could to distract myself from some heartbreak that was unbearable almost all of the time. Don’t close the tab just yet, I’m mostly past it now, most of what’s left is just reflecting.
I wanted to try to remember some of the things that I make, because maybe that would make them feel more real. Visual art came into my life very late, and I haven’t quite shaken the feeling that I’m not invited. I’ve been led to believe that visual artists have a medium, and I don’t really have the discipline to maintain one of those. Music has instruments and genres, but since synthesis and hip-hop have made a mess of those they never felt quite so intimidating.
Not really expecting anyone but me to get much joy out of them, but here are some things that I’ve made because I sorta had to.
With Music
Music is subtly but potently visual to me, and while I haven’t quite gotten to the point that I can make video with my own music, I do love making videos to other people’s music.
Murmuration (2020.02.10)
The sun was just starting to come back to Eugene and I was putting some periods on some memories. Things were bulging and shifting and nothing really felt settled. There were some nice winter sunsets though.
This is a simple lil glitch, a pulsed p-frame duplication with an RGB channel shift. The blooming effect from 00:48 to 00:54 was what I was itching for. Most of the beauty comes from the source video, a starling murmuration.
Music: Laura Jean Anderson - thinkin bout you
Thao & The Get Down Stay Down - A Man Alive (2020.01.27)
A) I love this album, and B) it was saying exactly what I was feeling at the time. These were three songs that I thought summed my bittersweet ass up relatively neatly (you know I’m so easy to find, you won’t come get your girl).
Technically very simple, rgb shift and a bunch of manual time warping & splicing.
Endless Love
Departure
Guts
Guillotine (2019.12.02)
Someone I like on Twitter posted some video using visbeat and so I made a bunch of deathgrips memes. this was my favorite one.
video: Arthur Ganson, The First Noble Truth
Nick Hakim - Miss Chew (2019.11.02)
We had a party at my house and I had taken some MDMA that had some little extra kick in it that made my eyeballs spin out of my sockets. When I could focus my vision again I started synthesizing video to project over the dancefloor i mean our living room. A housemate of mine that loves horror movies had suggested we watch Nosferatu the night before so I was using that as some of the source material. Burned a bunch of music into a good place in my heart.
The next day I had a sentimental hangover, my heart was vacant, mostly I was full of missing. Another simple p-frame duplication with a little random hex noise thrown into the encoded video stream before it gets decoded.
Tirzah - Affection (2019.10.22)
I was in an unexpected new depth in a hopeless argument with my heart, bargaining with my memories and promising to change, and working on a bunch of computer vision code. I started shooting video as a demo of the code for my collaborators, but got lost in its sort of numbing sparseness.
I can’t really describe the process for this one – the source video is some computer-vision glitch that I just kept pushing my thumb into until it looked right. Then I lost a few days layering and cutting the clips until it was done.
Webzones
Perlin Particles (2020.01.19)
A friend and mentor who is a recently-minted PI asked me to make her a lab website. This ended up being the central design element, but along the way I made a version just to play with.
Particles on 2D perlin noise. I think this one does better without documentation, just play with the slideys and see.
how to never get hired for any job pt 2. (2019.12.19)
My about me page is sorta an anti-about me page… while I was still getting used to having to be professional all the time it seemed super weird to me to have an entire page just describing yourself. So right now the page just indeciperably refers to my feelings about having people look at an “about me” page about me. I was trying to fix that and got lost along the way. The idea was to have my information passing by on these mountains and to make the user move their mouse to make certain regions lie flat long enough to read. I decided that sucks and that I should just make a real one, but inner me is holding up the timeline.
Speeding Atlas (2019.11.15)
If you combine the Stanford Open Policing Project data with transportation department road use data and assume that speeding is roughly equally likely on all roads, you can make a map of the roads that you are more or less likely to get a speeding ticket on. This is a map for just Washington state because other states have less data available and beacause I realized what a huge waste of time this was.
Map made with leaflet in R.
~alternative media~
instagram filters (2020.01.19)
I found out they let just anyone make instagram filters, and their platform is actually really lovely. I just made a few, not very good but i laughed a few times.
First a classic tinyface just to see how it works:
The I made a Mitt Romney face (and my housemate used it to watch Sex and the City):
And then Hank. Took a lot to make the 3d model of the head and face work together, and to add a lil cherry on top you get a coupla catch phrases when u open your mouth.
Autopotterotica (2020.01.01)
um.
Where to start with this one.
Fanfiction is, at least to me, one of the strangest but most beautiful human instincts. The raw diversity and volume of wish-fulfillment that happens within the bounds of fanfiction positively fucks up the elevation of my jaw. So I thought it might be interesting to have a neural net generate some.
It turns out fanfiction.net is the largest natural language text corpus that I’ve ever been able to find by orders of magnitude – 1.5T compressed text, hundreds or thousands of wikipedias. The scrape took ~7 weeks of 24/7 scraping.
I’ve never written fanfiction, but I did read a lot of experimental erotica at backyard poetry readings in college, and it quickly became clear what the neural net wanted to write.
These stories are all 100% neural-net generated (finetuned GPT-2) text. They are about 50% fully-random initializations and 50% initializations with seed text, but it didn’t take much. The only editing I do is cutting repetetive text, formatting into paragraphs, and minor fixes to punctuation – I don’t add anything or change its order. These are just a sample, I’m looking to finish the book during this great pause.
So, first, the scraping code for those for whom it would be useful, and then the smut for which I request you not put me in jail for.
list_stories.py - get a list of all available stories and their metadata
import requests
from bs4 import BeautifulSoup as bs
from tqdm import tqdm, trange
import json
import os
import tables
import pandas as pd
import numpy as np
import pdb
import traceback
import os
import multiprocessing as mp
import argparse
BROWSE_FANFIC = {
'anime': 'https://www.fanfiction.net/anime/',
'book': 'https://www.fanfiction.net/book/',
'cartoon': 'https://www.fanfiction.net/cartoon/',
'comic': 'https://www.fanfiction.net/comic/',
'game': 'https://www.fanfiction.net/game/',
'misc': 'https://www.fanfiction.net/misc/',
'play': 'https://www.fanfiction.net/play/',
'movie': 'https://www.fanfiction.net/movie/',
'tv': 'https://www.fanfiction.net/tv/'
}
def list_universes():
"""
List all story universes available on fanfiction.net and the number of stories they have
"""
rows = []
for fanfic_type, browse_page in tqdm(BROWSE_FANFIC.items(), position=0):
page = bs(requests.get(browse_page).content, 'lxml')
link_groups = page.find(id="list_output").find_all('div')
for l in tqdm(link_groups, position=1):
link = l.find('a')
story_num = l.find('span').text.lstrip('(').rstrip(')')
if story_num.endswith('K'):
story_num = int(float(story_num.rstrip('K'))*1000)
else:
story_num = int(story_num)
rows.append((fanfic_type, link.text, story_num, 'https://www.fanfiction.net'+link.get('href')))
return pd.DataFrame.from_records(rows, columns=('type', 'universe', 'n_stories', 'url'))
def list_stories(row):
"""
For a particular story universe, list all stories and return their metadata.
Args:
row (tables.Row): row containing metadata from list_universes()
"""
try:
i, row = row
# FIXME: hardcoding base_dir
base_dir = os.path.join(os.getcwd(), 'stories')
save_fn = os.path.join(base_dir, row.universe.replace('/','-')+'.pck.gz')
if os.path.exists(save_fn):
return
stories = []
first_page = bs(requests.get(row.url+"?&srt=1&r=10").content, 'lxml')
# find last page
try:
last_page_url = first_page.find('center').find('a', text='Last').get('href')
last_page = int(last_page_url.split('&p=')[-1])
except AttributeError:
last_page = 1
# get current process number to place progress bar
try:
current = mp.current_process()
tqdm_position = current._identity[0]+1
except:
tqdm_position = 0
story_pbar = tqdm(position=tqdm_position, total=row.n_stories)
# iterate through pages listing stories and get their metadata
for page_num in range(1,last_page+1):
page_url = row.url + '?&srt=1&r=10&p={}'.format(page_num)
page = bs(requests.get(page_url).content, 'lxml')
links = page.find_all(class_='z-list')
for l in links:
story_url = l.find(class_='stitle').get('href')
story_id = int(story_url.split('/')[2])
story_name = l.find(class_='stitle').text
story_url = 'https://fanfiction.net' + story_url
stories.append((row.universe, story_id, story_url, story_name))
story_pbar.update()
story_df = pd.DataFrame.from_records(stories, columns=('universe', 'id', 'url', 'name'))
story_df.to_pickle(save_fn, compression='gzip')
except Exception as e:
print(e)
pdb.set_trace()
def list_hp(url):
page = bs(requests.get(url).content, 'lxml')
links = page.find_all(class_='z-list')
stories = []
for l in links:
story_url = l.find(class_='stitle').get('href')
story_id = int(story_url.split('/')[2])
story_name = l.find(class_='stitle').text
story_url = 'https://fanfiction.net' + story_url
stories.append(('Harry Potter', story_id, story_url, story_name))
story_df = pd.DataFrame.from_records(stories, columns=('universe', 'id', 'url', 'name'))
return story_df
def list_harry_potter():
pool = mp.Pool(12)
base_url = 'https://www.fanfiction.net/book/Harry-Potter/'
# FIXME: hardcoding base_dir
base_dir = os.path.join(os.getcwd(), 'stories')
save_fn = os.path.join(base_dir, 'Harry Potter'+'.pck.gz')
if os.path.exists(save_fn):
return
first_page = bs(requests.get(base_url+"?&srt=1&r=10").content, 'lxml')
# find last page
try:
last_page_url = first_page.find('center').find('a', text='Last').get('href')
last_page = int(last_page_url.split('&p=')[-1])
except AttributeError:
last_page = 1
page_urls = [base_url + '?&srt=1&r=10&p={}'.format(n) for n in range(1, last_page+1)]
pbar = tqdm(total=len(page_urls), position=0)
pdb.set_trace()
results = pool.imap_unordered(list_hp, page_urls)
pages = []
for r in results:
result = r.get()
pages.append(result)
pbar.update()
hp_df = pd.concat(pages)
hp_df.to_pickle(save_fn, compression="gzip")
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument('--universes', help='location of the universes.json file that tracks which stories we need to reload')
parser.add_argument('--stories', help='location of stories directory - links to all stories')
parser.add_argument('--list', help='only list stories')
args = parser.parse_args()
if args.universes:
universe_path = args.universes
else:
universe_path = 'universes.json'
if args.stories:
story_path = args.stories
else:
story_path = os.path.join(os.getcwd(),'stories')
if not os.path.exists(story_path):
os.mkdir(story_path)
# list universes, if we have a previously available universes file,
# find universes that have more stories than we had last time.
universes = list_universes()
try:
past_universes = pd.read_json(universe_path)
universes = universes.loc[universes.n_stories > past_universes.n_stories,]
except:
print('\ncouldnt load old universes directory, loading all\n')
universes.to_json(universe_path)
# start a pool of workers to list stories
pool = mp.Pool(12)
#
# list_harry_potter()
pbar = tqdm(total=universes.shape[0], position=0)
results = pool.imap_unordered(list_stories, universes.iterrows())
for r in results:
try:
r.get()
pbar.update()
except AttributeError:
pbar.update()scrape_fanfiction.py - scrape all the fanfiction in the universe!!!
import requests
from bs4 import BeautifulSoup as bs
from tqdm import tqdm, trange
import json
import os
import tables
import pandas as pd
import numpy as np
import pdb
import traceback
import os
import multiprocessing as mp
import argparse
class Metadata(tables.IsDescription):
"""
Class to describe columns in metadata table
"""
page_id = tables.UInt32Col()
page_title = tables.StringCol(512)
title = tables.StringCol(512)
description = tables.StringCol(2048)
rating = tables.StringCol(64)
language = tables.StringCol(128)
chapters = tables.UInt16Col()
chapter = tables.UInt16Col()
words = tables.UInt64Col()
reviews = tables.UInt32Col()
favs = tables.UInt32Col()
follows = tables.UInt32Col()
updated = tables.StringCol(64)
published = tables.StringCol(64)
text_idx = tables.UInt64Col()
genre = tables.StringCol(256)
characters = tables.StringCol(512)
universe = tables.StringCol(1024)
def scrape_page(page, page_id, chapter=1, row=None):
"""
Scrape a single page
"""
# gather page elements with metadata
# small sub element with hyphen-separated descriptors
profile = page.find(id="profile_top")
subheader = list(profile.find(class_='xgray xcontrast_txt').children)
subhead_1 = [t.strip() for t in subheader[2].split('-')]
subhead_2 = [t.strip() for t in subheader[4].split('-')]
#############################
# gather metadata -- idiosyncratic selection criteria for the page and its format.
# after scraping several thousand pages, there are no obvious failures.
metadata = {}
# these ones are more or less always present, no position correction needed
metadata['page_id'] = page_id
metadata["page_title"] = page.find("title").text.encode('ascii', errors="ignore")
#metadata["title"] = profile.find("b").text.encode('ascii', errors="ignore")
metadata["description"] = profile.find('div', recursive=False).text.encode('ascii', errors="ignore")
metadata["rating"] = subheader[1].text.encode('ascii', errors="ignore")
metadata["language"], metadata["genre"], metadata["characters"] = subhead_1[1].encode('ascii', errors="ignore"), subhead_1[2].encode('ascii', errors="ignore"), subhead_1[3].encode('ascii', errors="ignore")
metadata['chapter'] = int(chapter)
# the following might be present, and so they require special checks
try:
metadata["chapters"] = [int(c.strip('Chapters: ')) for c in subhead_1 if c.startswith("Chapters:")][0]
except:
metadata['chapters'] = 1
metadata["words"] = [int(c.strip('Words: ').replace(',', '')) for c in subhead_1 if c.startswith("Words: ")][0]
try:
reviews_item = [r for r in subheader if 'Reviews' in r][0]
reviews_idx = subheader.index(reviews_item)
metadata["reviews"] = subheader[reviews_idx + 1].text
except:
pass
try:
metadata["favs"] = [int(c.strip("Favs: ").replace(',', '')) for c in subhead_2 if c.startswith('Favs')][0]
except:
metadata['favs'] = 0
try:
metadata["follows"] = [int(c.strip("Follows: ").replace(',', '')) for c in subhead_2 if c.startswith('Follows')][0]
except:
metadata['follows'] = 0
try:
updated_item = [r for r in subheader if 'Published' in r][0]
updated_idx = subheader.index(updated_item)
metadata["updated"] = subheader[updated_idx+1].text
except:
pass
try:
published_item = [r for r in subheader if 'Published' in r][0]
published_idx = subheader.index(published_item)
metadata["published"] = subheader[published_idx+1].text
except:
pass
#metadata["text_idx"] = texts.nrows
# add data from the row
metadata['universe'] = row.universe
metadata['title'] = row['name']
text = page.find(id="storytext").text
return metadata, text
def scrape_story(row):
"""
Scrape all pages of a story, including chapters.
"""
try:
i, row = row
global do_multi
if do_multi:
current = mp.current_process()
tqdm_position = current._identity[0]+1
else:
tqdm_position = 1
try:
url_id = str(row.id).zfill(7)
except:
url_id = row.id
page_url = "https://www.fanfiction.net/s/{}/".format(url_id)
page = bs(requests.get(page_url).content, 'lxml')
# determine whether a story is had here, if not skip this page.
try:
warning = page.find(class_="gui_warning")
if warning.text.startswith("Story Not Found"):
with open('fanfic_log.txt', 'a') as f:
f.write("Story not found, id: {}".format(row.id))
return [False], [False]
except AttributeError:
# didn't find warning, so Nonetype has no 'text'
pass
try:
# new error - weird blank page
warning = page.find(class_="gui_normal")
if warning.text.endswith("Please check to see you are not using an outdated url."):
with open('fanfic_log.txt', 'a') as f:
f.write("Outdated URL, id: {}".format(row.id))
return [False], [False]
except AttributeError:
pass
# figure out if story has chapters
chapter_select = page.find(id="chap_select")
if chapter_select:
has_chapters = True
else:
has_chapters = False
# scrape the first page and save data
metadata = []
text = []
metadata_1, text_1 = scrape_page(page, page_id=url_id, row=row)
metadata.append(metadata_1)
text.append(text_1)
# if the text has chapters, iterate.
if has_chapters:
n_chapters = len(list(chapter_select.children))
pbar = tqdm(position=tqdm_position, total=n_chapters)
for chapter_number in range(2, n_chapters + 1):
chap_url = page_url + str(chapter_number) + "/"
page = bs(requests.get(chap_url).content, 'lxml')
metadata_chap, text_chap = scrape_page(page, page_id=url_id, chapter=chapter_number, row=row)
metadata.append(metadata_chap)
text.append(text_chap)
pbar.update()
return metadata, text
except Exception as e:
with open('fanfic_log.txt', 'a') as f:
f.write(str(row))
f.write(str(e))
f.write(traceback.format_exc())
return [False], [False]
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument('--list', help='index file')
parser.add_argument('--output', help='output file path')
args = parser.parse_args()
if args.list:
list_path = args.list
else:
list_path = 'story_idx.pck.gz'
if args.output:
output_path = args.output
else:
output_path = 'fanfiction.h5'
print('\nreading story index')
stories = pd.read_pickle(list_path, compression='gzip')
print('\nstory index read, scraping {} stories'.format(stories.shape[0]))
# open hdf5 file to write to
filter = tables.Filters(complib='lzo', complevel=5)
h5f = tables.open_file(output_path, mode="a", title="fanfiction.net", filters=filter)
# if metadata table doesn't exist, make it, otherwise get the reference to it
try:
tab = h5f.create_table('/', "metadata", description=Metadata, filters=filter)
except tables.exceptions.NodeError:
tab = h5f.get_node('/', "metadata")
# same with texts, though we'll use a variable-length unicode
# format, which can only be a single column array.
try:
texts = h5f.create_vlarray(h5f.root, 'texts',
tables.VLUnicodeAtom(), filters=filter)
except tables.exceptions.NodeError:
texts = h5f.get_node('/', 'texts')
# remove stories that have already been scraped
print('loading ids of stories that have already been scraped...')
#scraped_ids = tab.col('page_id')
all_scraped_ids = []
scraped_ids = set()
i = 0
for row in tqdm(tab, total=tab.nrows):
if i>0 and i % 1000000 == 0:
all_scraped_ids.append(scraped_ids)
scraped_ids = set()
scraped_ids.add(row['page_id'])
i += 1
all_scraped_ids.append(scraped_ids)
scraped_ids = set().union(*all_scraped_ids)
print('looking for stories that have already been scraped (this might take a minute)...')
already_got = stories['id'].isin(scraped_ids)
print('\nAlready have {} stories, skipping those'.format(np.sum(already_got)))
stories = stories[~already_got]
# the row class allows us to write iteratively to the pytable
tab_row = tab.row
# figure out where we start & end. each page number is a 7-8 digit int.
global do_multi
do_multi = True
pbar = tqdm(total=stories.shape[0], position=0)
if not do_multi:
for arow in stories.iterrows():
metadata, text = scrape_story(arow)
for meta, tex in zip(metadata, text):
if not meta:
#print(meta, tex)
continue
for k, v in meta.items():
if isinstance(v, str):
v = v.encode('ascii', errors='ignore')
try:
tab_row[k] = v
except TypeError:
# could be a number with a comma..
v = int(v.replace(b',', b''))
tab_row[k] = v
tab_row.append()
texts.append(str(tex))
tab.flush()
texts.flush()
pbar.update()
else:
# create pool of workers
pool = mp.Pool(24)
results = pool.imap_unordered(scrape_story, stories.iterrows())
for r in results:
try:
#try:
#pdb.set_trace()
metadata, text = r
for meta, tex in zip(metadata, text):
if (not meta) and (not tex):
with open('fanfic_log.txt', 'a') as f:
f.write(str('skipping'))
continue
for k, v in meta.items():
if isinstance(v, str):
v = v.encode('ascii', errors='ignore')
try:
tab_row[k] = v
except TypeError:
# could be a number with a comma..
v = int(v.replace(b',', b''))
tab_row[k] = v
tab_row.append()
texts.append(str(tex))
tab.flush()
texts.flush()
pbar.update()
except Exception as e:
with open('fanfic_log.txt', 'a') as f:
f.write(str(e))
f.write(traceback.format_exc())
h5f.flush()
h5f.close()And the smut itself:
(download a pdf if the embed doesnt work)
schillbot (2019.10.03)
To get under the paper-thin skin of our university’s president while he was trying to balance the budget by taking medicine from graduate workers who make poverty wages, I made a twitter bot to mock him. The bot posted either a real quote or a neural-net generated quote and asked people to vote which one they thought it was.
I scraped all his often off-the-rails emails and writing from his website and trained a transformer model. This was before the proliferation of all these newfangled GPT-2 fine-tuned models, so it’s a little rough, but these are some of my favorites:
Look! even the wonderful Janelle Shane helped out!
neural net as activism: Univ of Oregon grad students, negotiating to save their health care benefits, raise awareness by training a bot on their university president's writing
— Janelle Shane (@JanelleCShane) October 5, 2019
via @GTFF_3544 https://t.co/4Jl1nx5fTo
"first we must provide services and I am committed to extraordinarily egregious cost-reduction goals" https://t.co/WnfYOHRvLG
— schillbot_3000 (@schillbot3000) May 20, 2019
"i know some of you read this, roll your eyes, but any of you who know me know i am a little boy." https://t.co/WnfYOHRvLG
— schillbot_3000 (@schillbot3000) October 22, 2019
"Full combat provost."
— schillbot_3000 (@schillbot3000) May 26, 2019
"i am committed to doing everything in my power to cushion the impact of this great university" https://t.co/WnfYOHRvLG
— schillbot_3000 (@schillbot3000) October 7, 2019
"please join me in this effort to address these issues as i apologize." https://t.co/WnfYOHRvLG
— schillbot_3000 (@schillbot3000) October 8, 2019
"over the past several months, we have experienced enormous churn in our boys by opening the doors of establish world-class research" https://t.co/WnfYOHRvLG
— schillbot_3000 (@schillbot3000) October 23, 2019
"i am announcing these decisions now because i am not know the victim or the pain they will be doing" https://t.co/WnfYOHRvLG
— schillbot_3000 (@schillbot3000) May 26, 2019
"i can go on to become one of the reasons why the university athletic fields will be in command of our state." https://t.co/WnfYOHRvLG
— schillbot_3000 (@schillbot3000) October 5, 2019
"during the summer months of that year, president michael schill shared his thoughts on the university's priorities: hard rock, my website" https://t.co/WnfYOHRvLG
— schillbot_3000 (@schillbot3000) October 14, 2019
red eyes on statues (2019.08.03)
A good friend sent me this:

So I copied it.
First I made some led-bombs by rigging them up to a 9V battery w/ a photodiode that turns the light off during the day to make them last longer.
Then I attached them to a few statues around UO. I didn’t really photograph or catch much video of this because I was basically in a fugue state from being deliriously heartbroken and it was maybe a little bit of vandalism.
Design
Autopilot (2019.10.17)
I released some software and wrote a paper to describe it, and I spent a lot of time to make a beautiful document. Typography is another art I am working to get better at, and I don’t really want to clutter up this post with a million page excerpts, but I am very proud of the way the figures are integrated with the text.
I will include the documentation logo that I like a lot though.
Union Propaganda
I don’t contribute enough to my union, but the one thing that I do contribute is a bit of design. These were all made during our most recent round of bargaining, which revealed what an amoral disaster of an institution the University of Oregon is.
uohellno.com
This was the website linked to by the schillbot. It works pretty badly on mobile (it was my first d3 scroller), so it will probably work even worse in this little iframe. may just want to visit uohellno.com
Salaries
Data available here: https://github.com/sneakers-the-rat/uoregon_salary_data
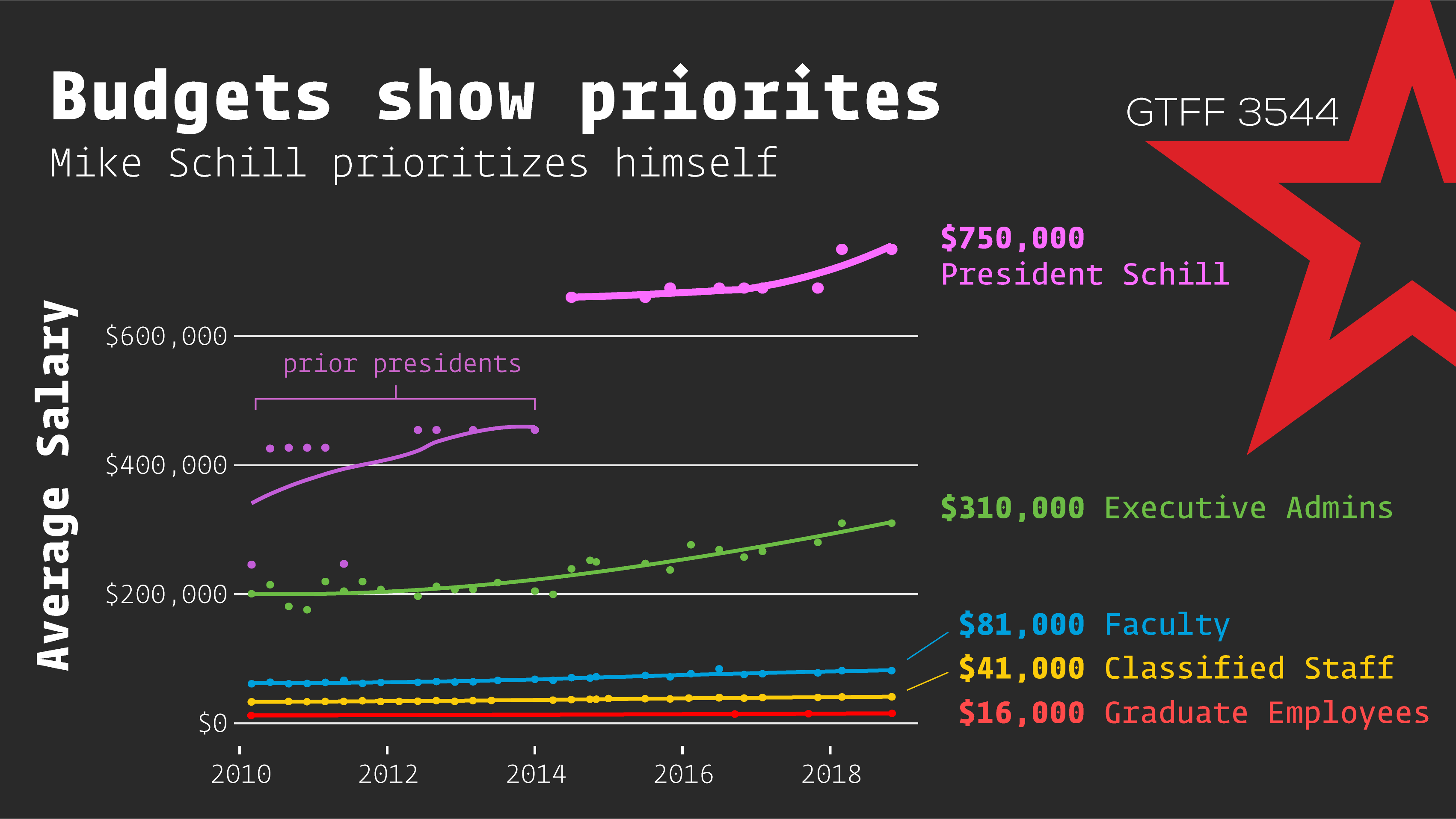
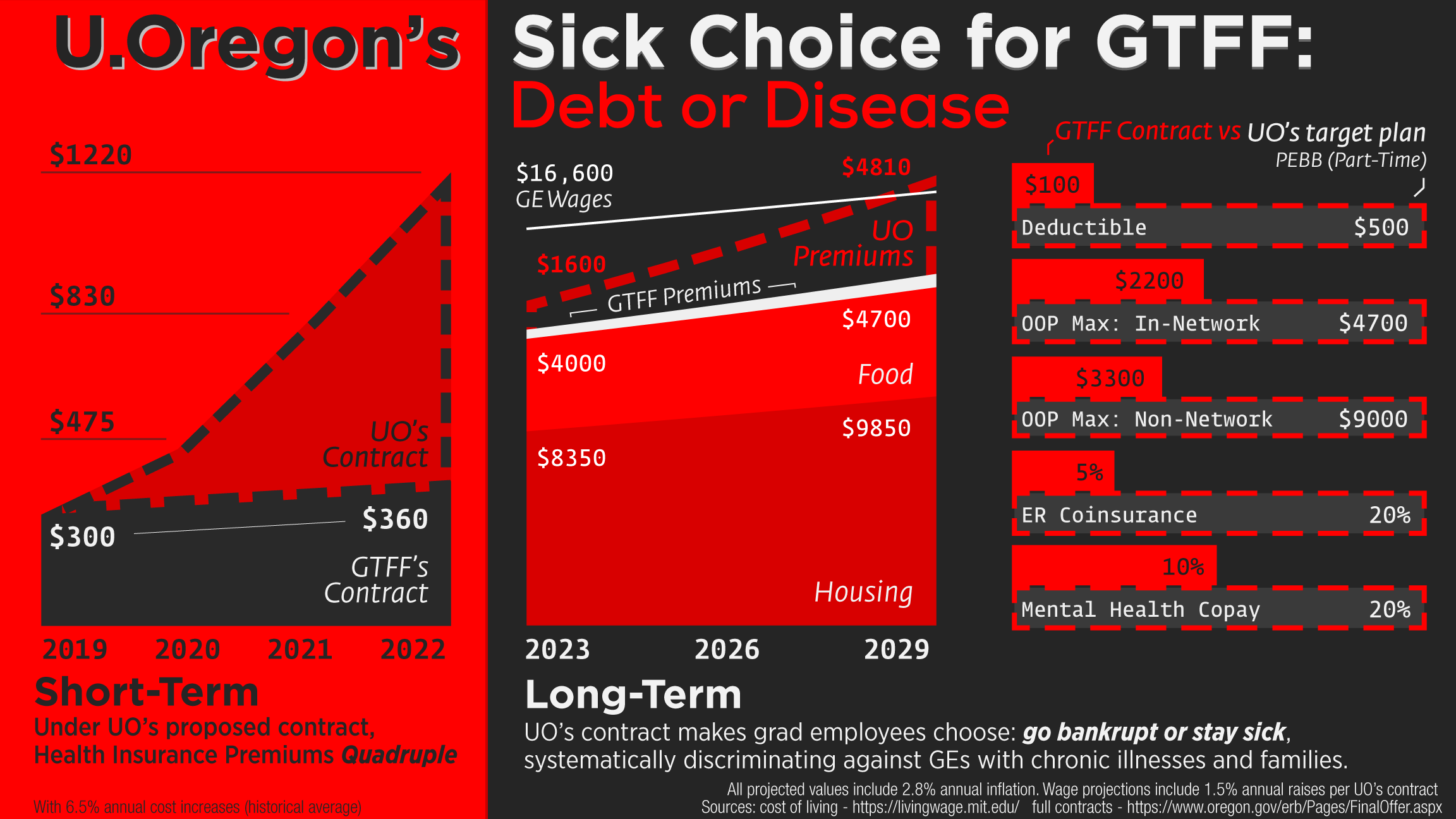
UOregon’s Healthcare Swindle
stupid bullshit projects
And finally, a bunch of other assorted scraps and pieces presented more or less without comment.

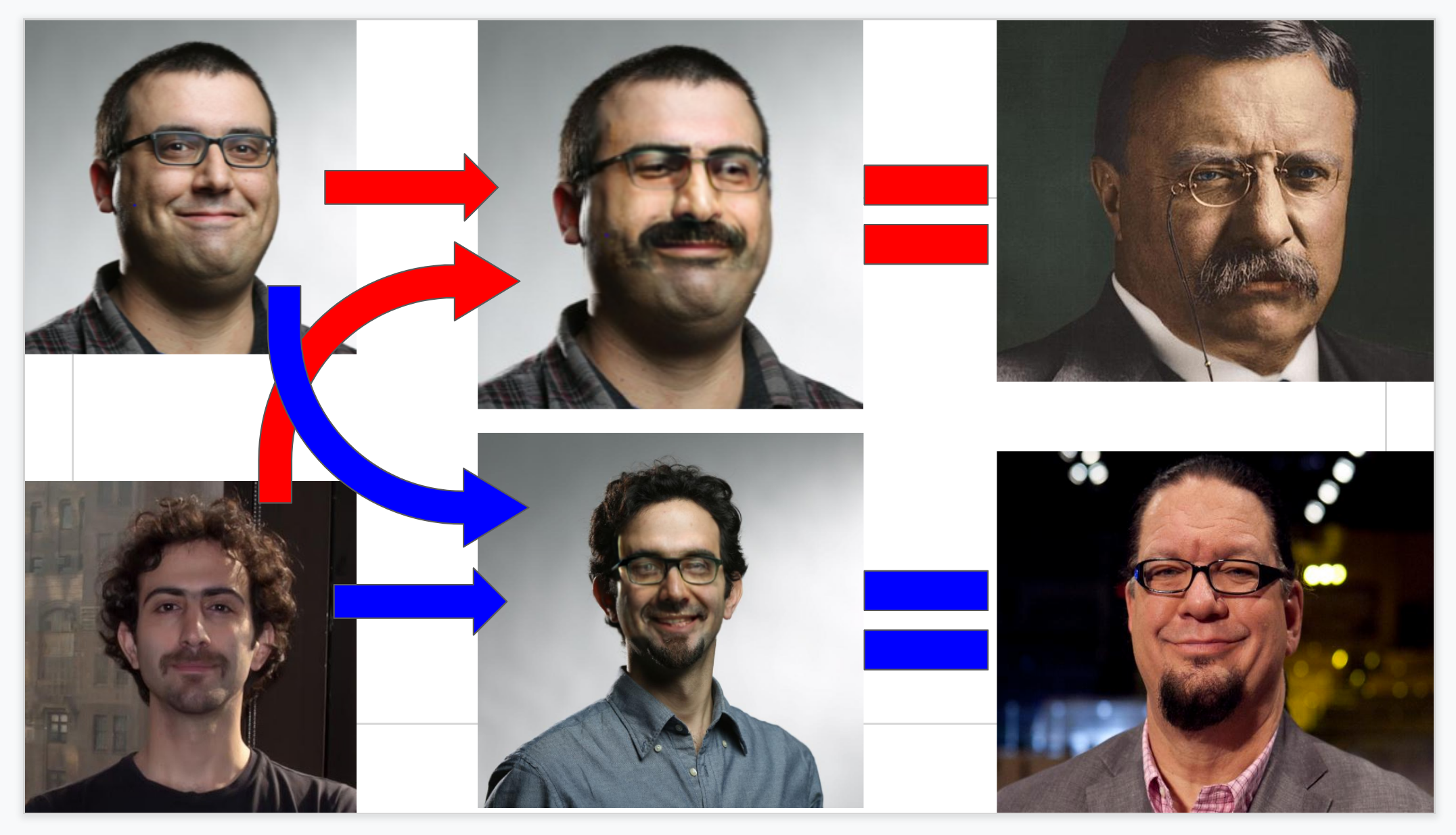
My department does “bullshit research talks” at our retreats, where someone makes a ridiculous presentation and someone else has to present it. Having someone I look up to very much present this neural-net face swap was one of my finest moments.

someone I love very much loves Selena very much, so this was for them.


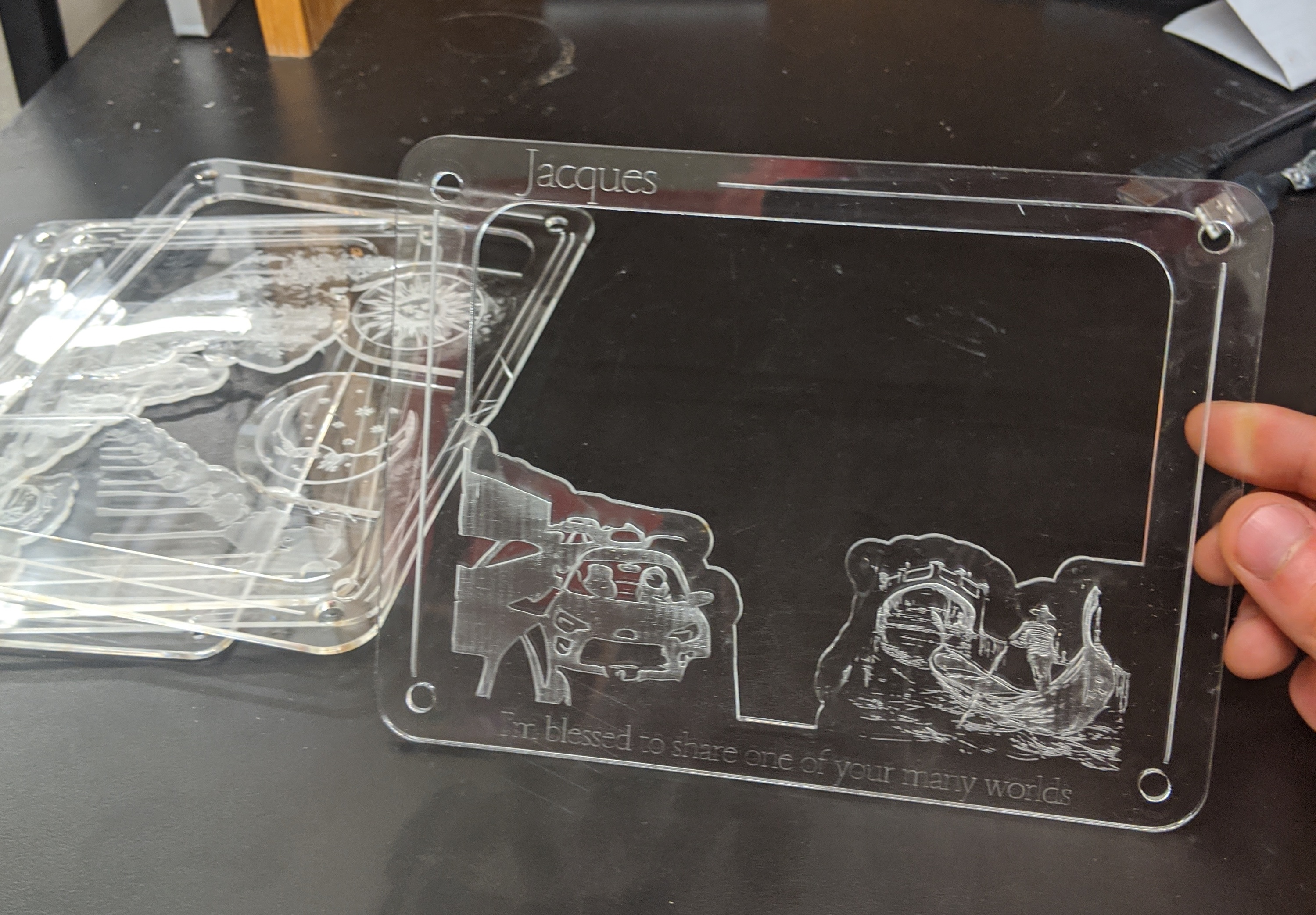
This was a gift I made for a dear dear friend that I unfortunately didn’t ever take a photo of the finished version. These panels stack together and have a few very fond memories in them. In this image: She is the sun, and i am the moon. one of the first memories I have with her is drunkenly fucking up someone else’s car radio (and it also fit iwth the scene), and nowadays I don’t see her much in part because she is busy all over the world <3.

Another dear dear friend got married last summer, and her maid of honor asked us to bring a photo of us together to their wedding. Shitty photoshop, but shitty photoshops are sorta one of the things we have a deep and shared love for.

schillbot (2019.10.03)
To get under the paper-thin skin of our university’s president while he was trying to balance the budget by taking medicine from graduate workers who make poverty wages, I made a twitter bot to mock him. The bot posted either a real quote or a neural-net generated quote and asked people to vote which one they thought it was.
I scraped all his often off-the-rails emails and writing from his website and trained a transformer model. This was before the proliferation of all these newfangled GPT-2 fine-tuned models, so it’s a little rough, but these are some of my favorites:
Look! even the wonderful Janelle Shane helped out!
neural net as activism: Univ of Oregon grad students, negotiating to save their health care benefits, raise awareness by training a bot on their university president's writing
— Janelle Shane (@JanelleCShane) October 5, 2019
via @GTFF_3544 https://t.co/4Jl1nx5fTo
"first we must provide services and I am committed to extraordinarily egregious cost-reduction goals" https://t.co/WnfYOHRvLG
— schillbot_3000 (@schillbot3000) May 20, 2019
"i know some of you read this, roll your eyes, but any of you who know me know i am a little boy." https://t.co/WnfYOHRvLG
— schillbot_3000 (@schillbot3000) October 22, 2019
"Full combat provost."
— schillbot_3000 (@schillbot3000) May 26, 2019
"i am committed to doing everything in my power to cushion the impact of this great university" https://t.co/WnfYOHRvLG
— schillbot_3000 (@schillbot3000) October 7, 2019
"please join me in this effort to address these issues as i apologize." https://t.co/WnfYOHRvLG
— schillbot_3000 (@schillbot3000) October 8, 2019
"over the past several months, we have experienced enormous churn in our boys by opening the doors of establish world-class research" https://t.co/WnfYOHRvLG
— schillbot_3000 (@schillbot3000) October 23, 2019
"i am announcing these decisions now because i am not know the victim or the pain they will be doing" https://t.co/WnfYOHRvLG
— schillbot_3000 (@schillbot3000) May 26, 2019
"i can go on to become one of the reasons why the university athletic fields will be in command of our state." https://t.co/WnfYOHRvLG
— schillbot_3000 (@schillbot3000) October 5, 2019
"during the summer months of that year, president michael schill shared his thoughts on the university's priorities: hard rock, my website" https://t.co/WnfYOHRvLG
— schillbot_3000 (@schillbot3000) October 14, 2019
red eyes on statues (2019.08.03)
A good friend sent me this:
So I copied it.
First I made some led-bombs by rigging them up to a 9V battery w/ a photodiode that turns the light off during the day to make them last longer.
Then I attached them to a few statues around UO. I didn’t really photograph or catch much video of this because I was basically in a fugue state from being deliriously heartbroken and it was maybe a little bit of vandalism.
Design
Autopilot (2019.10.17)
I released some software and wrote a paper to describe it, and I spent a lot of time to make a beautiful document. Typography is another art I am working to get better at, and I don’t really want to clutter up this post with a million page excerpts, but I am very proud of the way the figures are integrated with the text.
I will include the documentation logo that I like a lot though.
Union Propaganda
I don’t contribute enough to my union, but the one thing that I do contribute is a bit of design. These were all made during our most recent round of bargaining, which revealed what an amoral disaster of an institution the University of Oregon is.
uohellno.com
This was the website linked to by the schillbot. It works pretty badly on mobile (it was my first d3 scroller), so it will probably work even worse in this little iframe. may just want to visit uohellno.com
Salaries
Data available here: https://github.com/sneakers-the-rat/uoregon_salary_data
UOregon’s Healthcare Swindle
stupid bullshit projects
And finally, a bunch of other assorted scraps and pieces presented more or less without comment.
My department does “bullshit research talks” at our retreats, where someone makes a ridiculous presentation and someone else has to present it. Having someone I look up to very much present this neural-net face swap was one of my finest moments.
someone I love very much loves Selena very much, so this was for them.
This was a gift I made for a dear dear friend that I unfortunately didn’t ever take a photo of the finished version. These panels stack together and have a few very fond memories in them. In this image: She is the sun, and i am the moon. one of the first memories I have with her is drunkenly fucking up someone else’s car radio (and it also fit iwth the scene), and nowadays I don’t see her much in part because she is busy all over the world <3.
Another dear dear friend got married last summer, and her maid of honor asked us to bring a photo of us together to their wedding. Shitty photoshop, but shitty photoshops are sorta one of the things we have a deep and shared love for.